I modelli predittivi rappresentano strumenti della conoscenza con i quali è possibile stimare quantitativamente il risultato di un esperimento o l'evoluzione di un fenomeno.
Nella realtà di ogni giorno ne usiamo parecchi, spesso senza averne conoscenza. Le previsioni del tempo che vediamo in televisione, sono il risultato di un complesso modello predittivo basato sulle conoscenze delle leggi fisiche che governano la dinamica dell'atmosfera.
Quando le leggi che regolano il fenomeno sono sconosciute, i modelli predittivi si basano sulle osservazioni precedenti e sulle leggi della statistica e probabilità. Ad esempio la diagnostica, in molti campi, è in generale basata sulle osservazioni precedenti e, intuitivamente o esplicitamente, sul teorema di Bayes della statistica. Quando il modello è basato sulla conoscenza delle leggi che regolano il fenomeno, allora può essere utilizzato per verificare ipotesi e proporre nuovi esperimenti, diventando un potente strumento di indagine scientifica.
Per la sua utilizzazione pratica, il modello predittivo di un fenomeno complesso è implementato in software, il simulatore, che riproduce sul computer l'esperimento o il fenomeno. I simulatori sono tipicamente softwares complessi che richiedono tempi di calcolo spesso stimati in ore o giorni. Malgrado ciò, l' esecuzione di una simulazione è molto meno dispendiosa dell'esperimento di laboratorio in termini sia temporali sia economici. Per questo motivo le simulazioni sono ormai una realtà ampiamente utilizzata nell'industria meccanica ed elettronica in fase pre-prototipale.
La crescita delle tecnologie informatiche ha permesso di abbreviare i tempi di calcolo richiesti attraverso l'accresciuta potenza dei processori e la diffusione di strutture di calcolo distribuito e parallelo. Nel workshop che si è svolto a Catania il 22 e 23 gennaio scorsi, presso la sede del Parco scientifico e tecnologico della Sicilia, si è discusso dell' importanza di questi strumenti nella ricerca di nuovi farmaci.
Il percorso che porta alla scoperta del prodotto che acquistiamo in farmacia è caratterizzato inizialmente dall'identificazione di una sostanza chimica candidata, seguito da una serie di sperimentazioni prima di laboratorio (in vitro), poi su cavie animali (in vivo), e, per finire dalle tre fasi cliniche di sperimentazione in soggetti umani. Questo processo è molto selettivo: approssimativamente solo lo 0,1 % dei composti identificati nella fase iniziale è considerato sicuro per la sperimentazione clinica di fase I in soggetti umani.
Solo lo 0,02 % del pool di composti iniziale è finalmente approvato per essere commercializzato come farmaco per il trattamento della patologia. Questo significa che su 5000 composti chimici selezionati come possibili candidati per divenire un farmaco per una determinata patologia e sottoposti a sperimentazione di laboratorio e su cavie animali, solamente cinque possono accedere alla prima fase di sperimentazione clinica e solo uno viene approvato come farmaco.
Il tempo necessario per selezionare e sperimentare un composto che superi tutte queste fasi sperimentali è di circa 10-15 anni, dei quali circa 6-8 sono necessari per la fase di studi clinici e per ricevere l'approvazione finale da parte delle agenzie governative preposte alla vigilanza. Le spese sostenute (risorse umane, spese di laboratorio, ed altro) per le sperimentazioni sui composti che non hanno successo graveranno sul costo del prodotto finale. Considerato poi che i composti inizialmente selezionati non possono essere sperimentati contemporaneamente, ogni insuccesso allunga i tempi necessari alla commercializzazione del prodotto finale.
Nel processo di scoperta di un farmaco i modelli predittivi sono utili sia alla riduzione dei tempi, sia alla preselezione dei composti per i quali il modello prevede che l'esperimento abbia un risultato soddisfacente. Ovviamente un unico simulatore dell'intero processo che porta alla scoperta di un nuovo farmaco è inverosimile. E' tuttavia possibile costruire modelli e simulatori per le specifiche fasi.
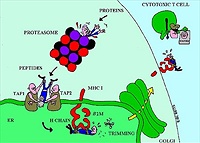
Nella prima quella in cui si identificano i composti potenzialmente attivi, cioè: l'approccio sistematico (rational drug design) basato sull'analisi di banche dati di composti e su metodologie di analisi mediante software (docking molecolare, relazione quantitativa struttura-attività, QSAR) è ormai utilizzato da molti anni con successo dai chimici farmaceutici.
Da qualche anno si è inoltre riconosciuto che l'utilizzo dei modelli e delle simulazioni giova anche nelle fasi successive del processo di costruzione di un farmaco. In un articolo di rassegna apparso nel settembre del 2006 su "Drug Discovery Today" (Neil Kumar, Bart S. Hendriks, Kevin A.Janes, David de Graaf, Douglas A. Lauffenburger - Applying computational modelling to drug discovery and development - vol.11, 806-811) i ricercatori del dipartimento di Ingegneria chimica del Centro di ricerca tecnologica della casa farmaceutica Pfizer e del dipartimento di Ingegneria biologica del Massachussets Institute of Technology identificano almeno quattro fasi del processo di ricerca e sviluppo del farmaco dove l'utilizzo dei modelli può incidere significativamente: i modelli per l'identificazione dell'obiettivo (target identification); i modelli che descrivono il complesso sistema di comunicazione che governa le attività basilari della cellula e coordina le azioni delle cellule (cell signaling); i modelli della risposta cellulare e infine, nella fase delle sperimentazioni in vivo, i modelli fisiologici.
Nel 2007 i ricercatori del Jenner Institute di Oxford, un centro specializzato nella ricerca di nuovi vaccini, hanno affrontato gli stessi argomenti per la scoperta dei vaccini. Questi ultimi sono farmaci che esplicano la loro azione stimolando il sistema immunitario, complessa ed integrata rete di mediatori cellulari e molecolari evolutasi per difendere l'organismo da qualsiasi forma di attacco che possa lederne l'integrità. La struttura del sistema immunitario richiede lo sviluppo di modelli complessi che devono essere eseguiti molte volte modificando i parametri che permettono di descrivere in modo stocastico la variabilità biologica.
Questo comporta l'utilizzo di risorse di calcolo distribuito notevoli che solo recentemente sono state realizzate in Sicilia dal Consorzio COMETA nell'ambito del progetto PI2S2 (www.pi2s2.it/).
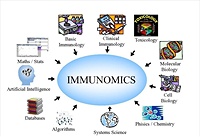
Il progetto europeo ImmunoGrid, al quale l'ateneo di Catania ha partecipato con il gruppo di Immunologia computazionale ed immunomica del dipartimento di Matematica e Informatica guidato da chi scrive (www.immunomics.eu), ha costruito modelli per lo studio della risposta immunitaria naturale ed indotta in alcune patologie: tumori, influenza, aterosclerosi, HIV.
Per educare le nuove generazioni all'uso dei modelli il progetto ha messo a disposizione la sezione "Education" del sito web (www.immunogrid.eu) dove gli studenti potranno, per i modelli proposti, simulare le diverse risposte immunitarie.